
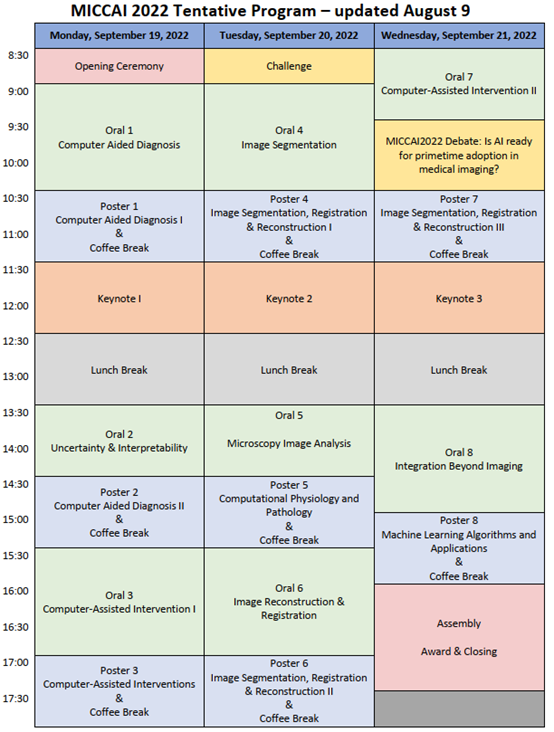
【PaperID: 10】Undersampled MRI Reconstruction with Side Information Guided Normalisation
Liu, Xinwen; In Person; Image Segmentation, Registration & Reconstruction III; Poster 7
Magnetic resonance (MR) images exhibit various contrasts and appearances based on factors such as different acquisition protocols, views, manufacturers, scanning parameters, etc. This generally accessible appearance-related side information affects deep learning-based undersampled magnetic resonance imaging (MRI) reconstruction frameworks but has been overlooked in the majority of current works. In this paper, we investigate the use of such side information as normalization parameters in a convolutional neural network (CNN) to improve undersampled MRI reconstruction. Specifically, a Side Information-Guided Normalisation (SIGN) module, containing only few layers, is proposed to efficiently encode the side information and output the normalisation parameters. We examine the effectiveness of such a module on two popular reconstruction architectures, D5C5 and OUCR. The experimental results on both brain and knee images under various acceleration rates demonstrate that the proposed method improves on its corresponding baseline architectures by a significant margin.
【PaperID: 16】BoxPolyp: Boost Generalized Polyp Segmentation using Extra Coarse Bounding Box Annotations
Wei, Jun;Virtual; Image Segmentation, Registration & Reconstruction I; Poster 4
Accurate polyp segmentation is of great importance for colorectal cancer diagnosis and treatment. However, due to the high cost of producing accurate mask annotations, existing polyp segmentation methods suffer from the severe data shortage and impaired model generalization. Reversely, coarse polyp bounding box annotations are more accessible.Thus, in this paper, we propose a boosted BoxPolyp model to make full use of both accurate mask and extra coarse box annotations. In practice, box annotations are applied to alleviate the over-fitting issue of previous polyp segmentation models, which generate fine-grained polyp area through the iterative boosted segmentation model. To achieve this goal, a fusion filter sampling (FFS) module is firstly proposed to generate more accurate pixel-wise pseudo labels from box annotations with less noise, leading to significant performance improvements. Besides, considering the appearance consistency of the same polyp, an inter-image consistency (IIC) loss is designed. Such IIC loss explicitly narrows the feature distance of the same polyp in different images, which yields the robust model against noisy annotations. Moreover, to enhance the reliability of pseudo labels, we further introduce a mixture of annotated and pseudo (MAP) labels strategy through simply pasting polyp patches with mask annotations into images with only bounding box annotations. Note that our BoxPolyp is a plug-and-play model, which can be merged
into any appealing backbone. Quantitative and qualitative experimental results on five challenging benchmarks confirm that our proposed model outperforms previous state-of-the-art methods by a large margin.

【PaperID: 153】SATr: Slice Attention with Transformer for Universal Lesion Detection
Li, Han; Virtual; Machine Learning Algorithms and Applications; Poster 8
Universal Lesion Detection (ULD) in computed tomography plays an essential role in computer-aided diagnosis. Promising ULD results have been reported by multi-slice-input detection approaches which model 3D context from multiple adjacent CT slices, but such methods still experience difficulty in obtaining a global representation among different slices and within each individual slice since they only use convolution-based fusion operations. In this paper, we propose a novel Slice Attention Transformer (SATr) block which can be easily plugged into convolution-based ULD backbones to form hybrid network structures. Such newly formed hybrid backbones can better model long-distance feature dependency via the cascaded self-attention modules in the Transformer block while still holding a strong power of modeling local features with the convolutional operations in the original backbone. Experiments with five state-of-the-art methods show that the proposed SATr block can provide an almost free boost to lesion detection accuracy without extra hyperparameters or unique network designs.

【PaperID: 359】 Rib Suppression in Digital Chest Tomosynthesis
Sun, Yihua; Virtual; Image Registration & Reconstruction Segmentation, II; Poster 6
Digital chest tomosynthesis (DCT) is a technique to produce sectional 3D images of a human chest for pulmonary disease screening, with 2D X-ray projections taken within an extremely limited range of angles. However, under the limited angle scenario, DCT contains strong artifacts caused by the presence of ribs, jamming the imaging quality of the lung area. Recently, great progress has been achieved for rib suppression in a single X-ray image, to reveal a clearer lung texture. We firstly extend the rib suppression problem to the 3D case at the software level. We propose a Tomosynthesis RIb SuPpression and Lung Enhancement Network (TRIPLE-Net) to model the 3D rib component and provide a rib-free DCT. TRIPLE-Net takes the advantage from both 2D and 3D domains, which model the ribs in DCT with the exact FBP procedure and 3D depth information, respectively. The experiments on simulated datasets and clinical data have shown the effectiveness of TRIPLE-Net to preserve lung details as well as improve the imaging quality of pulmonary diseases. Finally, an expert user study confirms our findings.

【PaperID: 361】 Stabilize, Decompose, and Denoise: Self-Supervised Fluoroscopy Denoising
Liu, Ruizhou; Virtual; Machine Learning Algorithms and Applications ;Poster 8
Fluoroscopy is an imaging technique that uses X-ray to obtain a real-time 2D video of the interior of a 3D object, helping surgeons to observe pathological structures and tissue functions especially during intervention. However, it suffers from heavy noise that mainly arises from the clinical use of a low dose X-ray, thereby necessitating the technology of fluoroscopy denoising. Such denoising is challenged by the relative motion between the object being imaged and the X-ray imaging system. We tackle this challenge by proposing a self-supervised, three-stage framework that exploits the domain knowledge of fluoroscopy imaging. (i) Stabilize: we first construct a dynamic panorama based on optical flow calculation to stabilize the non-stationary background induced by the motion of the X-ray detector. (ii) Decompose: we then propose a novel mask-based Robust Principle Component Analysis (RPCA) decomposition method to separate a video with detector motion into a low-rank background and a sparse foreground. Such a decomposition accommodates the reading habit of experts. (iii) Denoise: we finally denoise the background and foreground separately by a self-supervised learning strategy and fuse the denoised parts into the final output via a bilateral, spatiotemporal filter. To assess the effectiveness of our work, we curate a dedicated fluoroscopy dataset of 27 videos (1,568 frames) and corresponding ground truth. Our experiments demonstrate that it achieves significant improvements in terms of denoising and enhancement effects when compared with standard approaches. Finally, expert rating confirms this efficacy.

【PaperID: 422】 Meta-hallucinator: Towards few-shot cross-modality cardiac image segmentation
Zhao, Ziyuan; In Person; Image Segmentation, Registration & Reconstruction II; Poster 6
Domain shift and label scarcity heavily limit deep learning applications to various medical image analysis tasks. Unsupervised domain adaptation (UDA) techniques have recently achieved promising cross-modality medical image segmentation by transferring knowledge from a label-rich source domain to an unlabeled target domain. However,
it is also difficult to collect annotations from the source domain in many clinical applications, rendering most prior works suboptimal with the label-scarce source domain, particularly for few-shot scenarios, where only a few source labels are accessible. To achieve efficient few-shot cross-modality segmentation, we propose a novel transformation-consistent meta-hallucination framework, meta-hallucinator, with the goal of learning to diversify data distributions and generate useful examples for enhancing cross-modality performance. In our framework, hallucination and segmentation models are jointly trained with the gradient-based meta-learning strategy to synthesize examples that lead to good segmentation performance on the target domain. To further facilitate data hallucination and cross-domain knowledge transfer, we develop a selfensembling model with a hallucination-consistent property. Our metahallucinator can seamlessly collaborate with the meta-segmenter for learning to hallucinate with mutual benefits from a combined view of metalearning and self-ensembling learning. Extensive studies on MM-WHS 2017 dataset for cross-modality cardiac segmentation demonstrate that our method performs favorably against various approaches by a lot in the few-shot UDA scenario.

【PaperID: 1552】 Aggregative Self-Supervised Feature Learning from Limited Medical Images
Zhu, Jiuwen; Virtual; Machine Learning Algorithms and Applications; Poster 8
Self-supervised learning (SSL) is an efficient approach that addresses the issue of limited training data and annotation shortage. The key part in SSL is its proxy task that defines the supervisory signals and drives the learning toward effective feature representations. However, most SSL approaches usually focus on a single proxy task, which greatly limits the expressive power of the learned features and therefore deteriorates the network generalization capacity. In this regard, we hereby propose two strategies of aggregation in terms of complementarity of various forms to boost the robustness of self-supervised learned features. We firstly propose a principled framework of multi-task aggregative self-supervised learning from a limited sample to form a unified representation, with an intent of exploiting feature complementarity among different tasks. Then, in self-aggregative SSL, we propose to self-complement an existing proxy task with an auxiliary loss function based on a linear centered kernel alignment metric, which explicitly promotes the exploring of where are uncovered by the features learned from a proxy task at hand to further boost the modeling capability. Our extensive experiments on 2D natural image and 3D medical image classification tasks under limited data and annotation scenarios confirm that the proposed aggregation strategies successfully boost the classification accuracy.

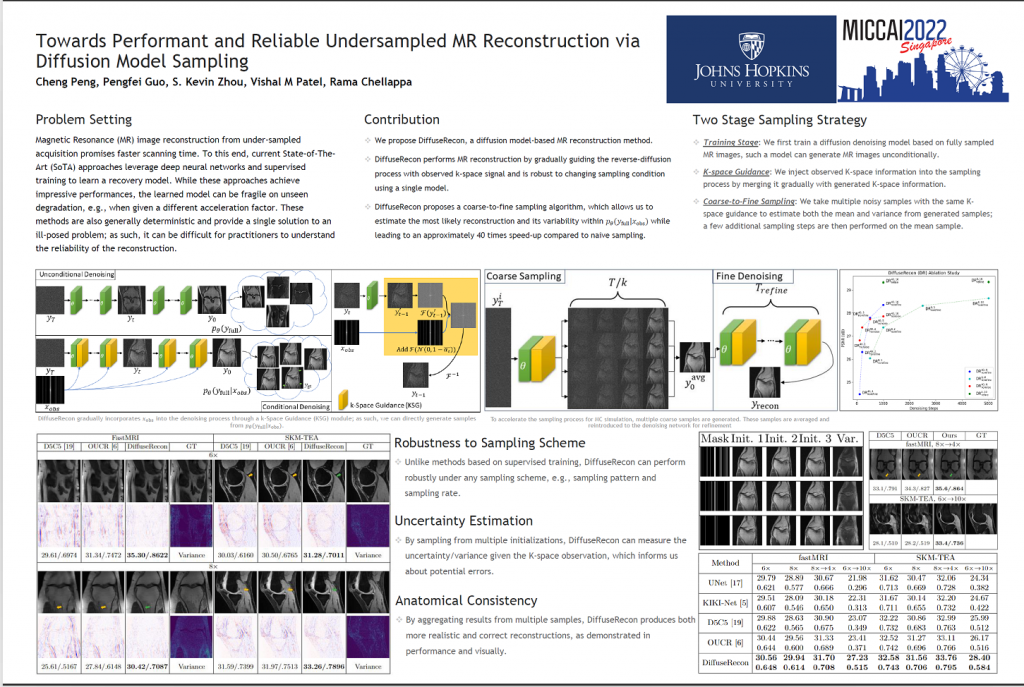
【PaperID: 1782】 Towards performant and reliable undersampled MR reconstruction via diffusion model sampling
Peng, Cheng; In Person; Image Segmentation, Registration & Reconstruction I; Poster 4
Magnetic Resonance (MR) image reconstruction from under-sampled acquisition promises faster scanning time. To this end, current State-of-The-Art (SoTA) approaches leverage deep neural networks and supervised training to learn a recovery model. While these approaches achieve impressive performances, the learned model can be fragile on unseen degradation, e.g. when given a different acceleration factor. These methods are also generally deterministic and provide a single solution to an ill-posed problem; as such, it can be difficult for practitioners to understand the reliability of the reconstruction. We introduce DiffuseRecon, a novel diffusion model-based MR reconstruction method. DiffuseRecon guides the generation process based on the observed signals and a pre-trained diffusion model, and does not require additional training on specific acceleration factors. DiffuseRecon is stochastic in nature and generates results from a distribution of fully-sampled MR images; as such, it allows us to explicitly visualize different potential reconstruction solutions. Lastly, DiffuseRecon proposes an accelerated, coarse-to-fine Monte-Carlo sampling scheme to approximate the most likely reconstruction candidate. The proposed DiffuseRecon achieves SoTA performances reconstructing from raw acquisition signals in fastMRI and SKM-TEA.
【PaperID: 1959】 Learning Incrementally to Segment Multiple Organs in a CT Image
Liu, Pengbo; Virtual; Image Segmentation, Registration & Reconstruction III; Poster 7
There exists a large number of datasets for organ segmentation, which are partially annotated and sequentially constructed. A typical dataset is constructed at a certain time by curating medical images and annotating the organs of interest. In other words, new datasets with annotations of new organ categories are built over time. To unleash the potential behind these partially labeled, sequentially-constructed datasets, we propose to incrementally learn a multi-organ segmentation model. In each incremental learning (IL) stage, we lose the access to previous data and annotations, whose knowledge is assumingly captured by the current model, and gain the access to a new dataset with annotations of new organ categories, from which we learn to update the organ segmentation model to include the new organs. While IL is notorious for its `catastrophic forgetting’ weakness in the context of natural image analysis, we experimentally discover that such a weakness mostly disappears for CT multi-organ segmentation. To further stabilize the model performance across the IL stages, we introduce a light memory module and some loss functions to restrain the representation of different categories in feature space, aggregating feature representation of the same class and separating feature representation of different classes. Extensive experiments on five open-sourced datasets are conducted to illustrate the effectiveness of our method.

【Workshop】DuDoTrans: Dual-Domain Transformer for Sparse-View CT Reconstruction
Wang Ce; Virtual; MICCAI Workslop–Machine Learning for Medical Imaging Reconstruction
While Computed Tomography (CT) is necessary for clinical diagnosis, ionizing radiation in the imaging process induces irreversible injury, thereby driving researchers to study sparse-view CT reconstruction. Iterative models are proposed to alleviate the appeared artifacts in sparse-view CT images, but their computational cost is expensive. Deeplearning-based methods have gained prevalence due to the excellent reconstruction performances and computation efficiency. However, these methods ignore the mismatch between the CNN’s local feature extraction capability and the sinogram’s global characteristics. To overcome the problem, we propose Dual-Domain Transformer (DuDoTrans) to simultaneously restore informative sinograms via the long-range dependency modeling capability of Transformer and reconstruct CT image with both the enhanced and raw sinograms. With such a novel design, DuDoTrans even with fewer involved parameters is more effective and generalizes better than competing methods, which is confirmed by reconstruction performances on the NIH-AAPM and COVID-19 datasets. Finally, experiments also demonstrate its robustness to noise.
